AIによる画像生成めちゃくちゃ熱いですね。
DALL·E 2に続き

Midjourney

そして、今回紹介する「Stable Diffusion」と立て続けにサービスが出ています。
ここまでクォリティーが高いものが簡単に生成できるとなるとゲームチェンジが起こるのではと思います。
デザインされたものを服とか靴にすることだって可能だし、そういったサービスが出てくるのではと。
「Stable Diffusion」もそうですが、かなりスペックの高いPCがないと簡単には利用できません。
検索してみると、以下の記事が見つかりました。
この方法であれば、無料でできるので、こちらを参考に環境を構築し、Stable Diffusionを試していきます。
画像生成AI「Stable Diffusion」を低スペックPCでも無料かつ待ち時間なしで使う方法まとめ - GIGAZINE
Hugging Faceのトークンを発行
Hugging Faceとは???は、以下の記事を参考ください。
自然言語処理のデータセット提供サイトで、「Stable Diffusion」のコードやドキュメントは、こちらで公開されているため、アカウントを作成してトークンを発行する必要があるそうです。
以下にアクセスします。

CompVis/stable-diffusion-v1-4 · Hugging Face

このモデルにアクセスするには、あなたの連絡先情報を共有する必要があります。
このリポジトリは一般に公開されていますが、コンテンツにアクセスするには登録が必要です。心配しないでください、ワンクリックするだけです
下の「リポジトリにアクセス」をクリックすると、あなたの連絡先(メールアドレスとユーザー名)がリポジトリの作者と共有されることに同意したことになります。これにより、例えばライセンス上の理由でリポジトリのコンテンツの一部を削除する必要がある場合、作者に連絡することができます。
このモデルを入手する前にもう一歩。
このモデルはオープンアクセスで誰でも利用でき、CreativeML OpenRAIL-Mライセンスでさらに権利と使用方法が規定されています。
CreativeML OpenRAILライセンスでは、以下のように規定されています。
1.あなたは、このモデルを使用して、違法または有害な出力やコンテンツを意図的に作成したり、共有したりすることはできません。
2.CompVisは、あなたが生成した出力に関する権利を主張しません。あなたはそれらを自由に使用することができ、ライセンスで設定された規定に反してはならないその使用について説明責任を負います。
3.3. あなたは、重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。その場合、ライセンスに記載されているものと同じ使用制限を含め、CreativeML OpenRAIL-Mのコピーをすべてのユーザーと共有しなければならないことに注意してください(ライセンスを完全にかつ注意深く読んでください)。
ライセンスの全文はこちらでご覧ください: https://huggingface.co/spaces/CompVis/stable-diffusion-license
下の "Access repository "をクリックすると、あなたの*連絡先*(メールアドレスとユーザー名)がモデルの作者とも共有されることに同意したことになります。
あなたはすぐにモデルのコンテンツにアクセスできるようになります。Access repositoryボタンをクリックして同意します。
するとログイン画面が表示されるので、「Sign Up」をクリックして新規登録をします。

アカウント作成画面が表示されるので、メールアドレス、パスワードを入力して、Nextをクリックします。

プロフィール入力が出るので、Username、Full name、同意のチェックをつけて「Create Account」をクリックします。

以下の画面に戻ります。

アカウント作成時のメールアドレスにメールが来ているので確認し、リンクを押してconfirmします。

メールアドレスの認証が完了すると、アカウントの作成が完了となります。

再度、以下のURLに戻ります。
CompVis/stable-diffusion-v1-4 · Hugging Face
ライセンスに同意するチェックをつけて、Access repositoryをクリックします。

以下のページが表示されます。

右上のプロフィールアイコンをクリックし、Settingsをクリックします。

Settingsページの左ナビから、「Access Tokens」を選択し、「New token」をクリックします。

適当な名前をつけて、「Generate a token」をクリックします。

以下のように作成されます。トークンの発行は以上になります。

Colaboratoryの準備
Colaboratoryとは???は、以下の記事を参考ください。

【初心者向け】無料で始めるGoogle Colab完全ガイド|基本操作・GPU設定・便利機能まで解説! - AI Academy Media
利用には、Googleアカウントが必要になります。(Googleのサービス)
以下に、アクセスします。

既にアカウントにログインしている状態だったため、以下のように表示されました。
未ログイン時は、ログインボタンが表示されるので、ログインをしてください。

「ノートブックを新規作成」をクリックします。

ノートブックが作成されたら「編集」「ノートブックの設定」をクリックします。

「GPU」を選択して「保存」をクリックします。

この環境に、「Stable Diffusion」をインストールします。
各種設定
Colaboratoryが無料利用だとリセットされるため、ここの手順はリセットされるたびに必要になります。
以下のコマンドを入力し、再生ボタンをクリックします。
pip install diffusers==0.2.4 transformers scipy ftfy
以下のように、表示されたら成功です。
Successfully installed diffusers-0.2.4 ftfy-6.1.1 huggingface-hub-0.9.0 tokenizers-0.12.1 transformers-4.21.2
続いて、Hugging Faceのトークンを設定します。
YOUR_TOKEN=”Hugging Faceで発行したトークン”
以下の画面で、青枠をクリックするとコピーできます。
URLは、https://huggingface.co/settings/tokens

コマンド入力欄に、以下のコマンドを入れて、再生ボタンをクリックします。
YOUR_TOKEN="Hugging Faceで発行したトークン"コマンドを追加で入力する際は、「+コード」をクリックして枠を追加します。

続けて、以下のコマンドを入力します。(YOUR_TOKENは、そのままで大丈夫です)
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)ダウンロードが始まります。私は、2分かかりました。

完了したら、再度コマンド欄を追加して、以下を実行します。
緑色のチェック(5秒の記載の上)が出たら、Stable Diffusionを使う準備は完了です。
pipe.to("cuda")
Stable Diffusionで画像を生成してみる
+ コマンドをクリックして、コマンド入力欄を追加します。
そして、以下のコマンドを入力し、再生ボタンを押してみます。
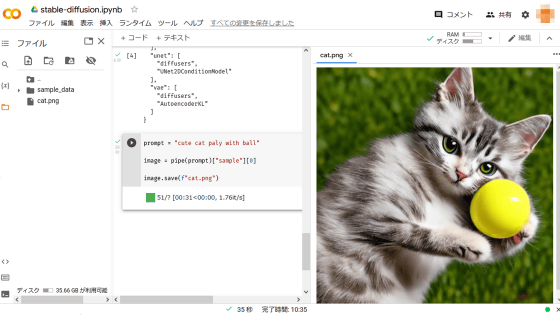
prompt = "cute cat paly with ball"
image = pipe(prompt)["sample"][0]
image.save(f"cat.png")実行に、36秒かかり、左ナビのファイルのところに、cat.pngが出来上がりました。

画像ファイルをダブルクリックすると右ペインに画像が表示されます。

三点リーダーをクリックして、ダウンロードをクリックするとDLできます。

猫の体しか描かれていませんでした。。。

他の画像生成を試す場合は、「+コマンド」からコマンド入力欄を追加して、以下のコマンドの英文と出力ファイル名を変えることで可能です。
prompt = "cute cat paly with ball" // ここの文章を変える
image = pipe(prompt)["sample"][0]
image.save(f"cat.png") // ここのファイル名を変える何度か試してみましたが、なかなか思うように絵が作成できません。
「stable diffusion 呪文」でtwitter検索するとこのキーワードを含めるとうまく生成できるといった呪文があるようです。
「makoto shinkai」
「Anime by Wlop」
ここらへんのキーワードをいれるといいみたいです。
呪文を唱えられる人が重宝されていくのでしょうか。
pipeの引数でいくつか設定ができるようです。
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
batch_size = len(prompt)Google Colabには以下の制限があるので注意しましょう。
・RAM:12GB
・ディスク:CPU/TPC:最大107GB、GPU:最大68GB
・90分ルール : 何も操作せずに90分経つとリセット
・12時間ルール : インスタンスが起動してから12時間経つとリセット
・GPUの使用制限 : GPUを使いすぎるとリセット(上限未公開)
翌日に同じものを利用して、描画を行おうとしたらエラーとなりました。
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-a01812185ea9> in <module>
1 prompt = "a photograph of an astronaut riding a horse"
----> 2 image = pipe(prompt, height=512, width=768)["sample"][0]
3
4 image.save(f"horse.png")
NameError: name 'pipe' is not defined12時間ルール : インスタンスが起動してから12時間経つとリセット
こちらが影響しているものと思われ、各種設定の項を再実行する必要があります。
また、生成した画像も消えてしまうので、DLしておきましょう。
最初に生成した以下の命令ですが、文章を以下のように変えるとこのような絵に変わりました。
prompt = "cute cat paly with ball" // ここの文章を変える
image = pipe(prompt)["sample"][0]
image.save(f"cat.png") // ここのファイル名を変える変更後
prompt = "cute cat paly with ball, professionally retouched, soft lighting, wide angle, 8 k high definition, intricate, elegant, art by brian miller, peter mohrbacher"
image = pipe(prompt)["sample"][0]
image.save(f"cat.png")
見違える絵になりました。
真四角になるので、以下のようにサイズを指定しておくと良さそうです。
image = pipe(prompt, height=512, width=768)["sample"][0]呪文のサイトがありました。
生成されるイメージとキーワードの組み合わせを確認することができます。
こちらのサイトのキーワードを参考に、以下のコマンドを実行してみました。(Bokeh effectを追加)
prompt = "cute cat paly with ball, professionally retouched, soft lighting, wide angle, 8 k high definition, intricate, elegant, art by brian miller, peter mohrbacher, Bokeh effect"
image = pipe(prompt, height=512, width=768)["sample"][0]
image.save(f"cat.png")
明確な違いは見られませんでした。
「Lens flare effect」も試してみます。
prompt = "cute cat paly with ball, professionally retouched, soft lighting, wide angle, 8 k high definition, intricate, elegant, art by brian miller, peter mohrbacher, Lens flare effect"
image = pipe(prompt, height=512, width=768)["sample"][0]
image.save(f"cat.png")
なかなか難しいw
Stable Diffusion 1.5を試して見たい方は、こちらを参考にしてみてください。
